Keeping track of my research day activities!
2021 – 2022 Research Days
I haven’t done such a great job of keeping track of my research day activities over the past year, but here are some of the highlights:
October 20 & 21, 2022
CAUT Librarian and Archivist Conference: I enjoyed attending this conference virtually on the 20th and 21st. It focused on collective action and labour, and I was especially grateful for the workshop and case studies on the 21st.
Conference fee covered by UTFA.
October 3 – 6, 2022
CRKN Conference: Strength in Community: At this conference I had the pleasure of presenting about the Indigenous Metadata Working Group with Maria Aleluia.
April 26 & 27 2022
Concordia Research Forum: I had the pleasure to present Truth Talking in The Library: A Thematic Investigation of Statements on Bias in Libraries and Archives with Cora Coady and Tina Liu. Slides and presentation recording are available on the conference website.
March 31, 2022
Preparing for the Concordia Research Forum and continuing to look at text and data mining.
March 3, 10, 17, 24, & 31 2022
One of the highlights of events I attended during this stretch of research days was:
Text and Data Mining (TDM) in Research: Applications and Tools.
Text and data mining is the science of extracting information, identifying patterns, or knowledge from large bodies of text, in the case of text mining, or data, in the case of data mining*. Researchers have used text and data mining in various ways such as abstract screening for knowledge synthesis, determining changes in human languages, and generally detecting patterns, trends and drawing new conclusions from large datasets.
The Centre for Research Innovation & Support (CRIS) in collaboration with the University of Toronto Libraries (UTL) is hosting a session on text and data mining in research. This session will highlight how various researchers apply text and data mining methods to their research. Researchers will share their knowledge and experience on the application of text and data mining tools in analyzing large datasets, and showcase examples to illustrate the potential utility of these tools for different research use cases.
*Definition adapted from Universityof Toronto Libraries website
Panelists:
- Kelly Schultz (Moderator) – Data Visualization Librarian, Lead – Text and Data Mining, from the Map and Data Library, University of Toronto
- Dr. Michelle Alexopoulos – Professor in the department of Economics at the University of Toronto.
- Dr. Frank Rudzicz – Associate Professor, Department of Computer Science at the University of Toronto
November 8, 2021
January 29, April 9, April 23, 2021
The last few research days that I have taken have been incredibly busy and focused on my project to analyze the geographic subject headings, in preparation for delivering a presentation on the work at NASIG 2021. Data cleaning took me much longer than anticipated…
If you want to check out the final products or reuse the data, it’s available on github:
https://github.com/JordanPedersen/pymarc-extraction/blob/main/pymarc_extract.py
https://github.com/JordanPedersen/nasig_2021
The full presentation was recorded and is available here:
https://www.youtube.com/watch?v=02A4NcR2Zv0
And for anyone who is interested here are the slides as well:
December 14 – 15, 2020
This year has flown by professionally, and it felt like a good idea to take some research days. Now that things have been less busy with regards to the LSP during regular working hours, I’ve had more time to think about research projects, and I’m excited to be starting on a new project!
To give some backstory, when I was interviewing for my current position, I was ruminating on the idea of metadata as an object of study, not just descriptors (similar to the way that book scholars study the physical object of the book and not the contents of the written word). That, combined with my recent PD-learning opportunities about building diverse collections and, using python for data analysis, has led me to start analyzing MARC subject fields as markers of collection diversity.
So far, I’ve extracted all of the 6XX fields in use at UTL (there’s over 20 million), and I’ve started iterating through data cleaning and running some exploratory analyses in a JUPYTER notebook. I also started working on a proposal for a journal about this work, as well as a conference. I’m really excited to share code that I’m working on once it’s done, but for now, some screenshots…
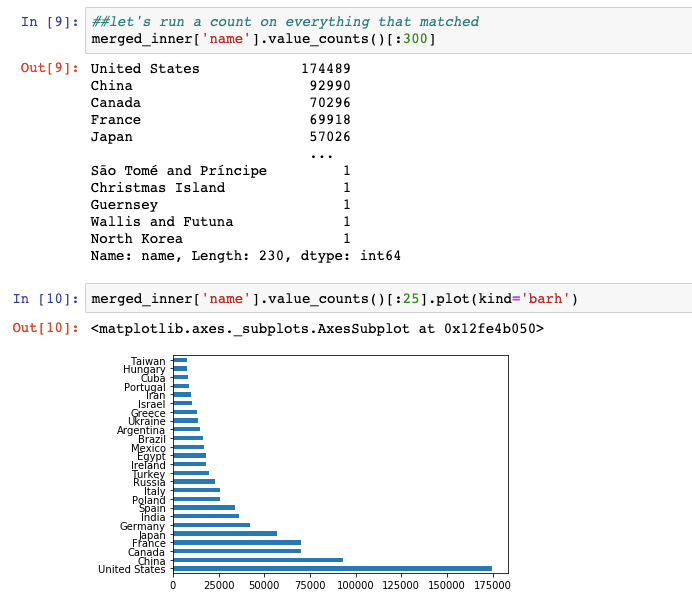

October 19 – 23, 2020
Access Conference and LJ Equity in Action: Building Diverse Collections workshop pt. 1!
This week was super full and busy (both with LSP-related stuff at work, and attending a conference, workshop, and UTL research event). But, to keep on topic for this blog, I’ll focus on the half-research-days I took all week (which enabled me to attend most of the events I wanted to!).
Access Conference
As an added bonus, there was a collaborative note taking document, so you can access notes from all the presentations here.
Sessions I attended:
- The (sometimes false) promise of technology in Indigenous language revitalization by Jessie Loyer
- What is the right thing to do? Looking at LIS practice through the lens of professional ethics by Scott Young
- A series of unfortunate events: Managing a Library IT meltdown during COVID-19 by David Kemper
- Best practices in data visualization by Thilani Samarakoon
- What is a library website, anyway? by Amy McLay Paterson
- Making a harvester harvestable: Federating an OAI endpoint directly from Postgres by Kelly Stathis and Alex Garnett
- Library projects using Agile or traditional project management: Less stress and more success by Trevor Smith
- Selling Infrastructure as a Service to faculty by Tim Ribaric
- The power of choice: A Choose Your Own Conference presentation by Ruby Warren
- Sharing is caring: Community-led resource sharing from the ground up by Brian Lin and Kristen Wilson
- The Carpentries as driver of communities of practice in large institutions by Elizabeth Parke and May Chan
Equity in Action: Building Diverse Collections
I started checking out the course shell and introducing myself. I’m excited to be taking this course with about 12 colleagues from UTL. In the first round of live sessions, we heard from:
- What Is a Diverse and Inclusive Collection? by Mahnaz Dar
- Collection Management Strategies to Enact Change at Your Library by Robin Bradford
- Conducting a Diversity Audit of Your Collections by Karen Jensen
August 14, 21, 28, and September 3, 2020
What a whirlwind couple of weeks! I took four Fridays off to host an International Library Carpentries workshop, which was fantastic. The process of planning an online workshop was certainly more intense than I originally anticipated, but I enjoyed the camaraderie and I can definitely say it was worth it.
Planning consisted of:
- Putting out a call for instructors and helpers, and then choosing the lessons we would teach. Thank you so much to Rachel Wang, Abigail Sparling, Lise Doucette, Nilani Ganeshwaran, Reid Otsuji, Stephanie Labou, Cody Hennesy, Thomas Guignard and Elaine Wong for responding and being such amazing helpers!
- Creating the workshop website
- Creating the sign-up page. We decided to reserve half of our seats for equitable access for people who self-identify as BIPOC and/or another underrepresented group in librarianship. If the 15 equitable access tickets were not claimed by Aug 7, the criteria opened to people who have faced geographic barriers when trying to access a carpentries workshop. Happily, we can say this approach worked wonders – although the main workshop “sold out” (we weren’t actually charging a fee but participants had to register) in just under 2 hours, it took the entire registration period for 14 equitable access tickets to be claimed. We had participants from 6 countries and from many workplaces – students, universities, public libraries, archives, government, and national broadcasters
- Email attendees with expectations
- Moderate each of the workshop sessions – go over daily “housekeeping”, create breakout groups, be available for questions, etc.
I had an amazing time, and look forward to whenever we can do this again!

April 15-17, 2020
While these research days have not been what I expected – I was originally planning on being in Richmond, British Columbia for the BC Library Conference – everything is requiring a lot of flexibility in these COVID-19 days. May Chan and I are still planning on giving our conference presentation virtually, but in the meantime I decided to use this time to start taking courses that will count towards the Library Juice Academy certificate in XML and RDF-Based Systems.
I’m currently enrolled in Introduction to RDF, and in May I will start RDF, RDFa and Structured Data Vocabularies. So far we’ve covered an introduction to the Semantic Web and RDF, as well as the components of RDF XML and an introduction to vocabularies and ontologies. Having worked with graph databases and RDF using python last fall, some of the course content is not new to me, but I have been enjoying the systematic way that the instructor introduces terms as well as the weekly chat sessions where we can ask questions. I now feel like I have a better handle on how to talk about RDF data for sure.

To supplement this work, I’ve decided to experiment with python packages to convert MARC records to RDF/XML. But first, I’d like to share some of the “failed” attempts that got me to this point…
- I tried following the instructions in the Converting MARC to RDF lightning talk by F. Tim Knight, and while the instructions were sparse but clear, I had issues processing my files using XSLT Style Sheets. I’m definitely going to revisit this method, but got impatient and decided to look for python packages instead.
- When searching for python alternatives, I came across a Code4Lib pre-conference session about Transforming MARC and Metadata into RDF-based Applications by Jeremy Nelson and Mike Stabile. They used a package called BIBCAT, however when I went to test it out, it wasn’t for me. The library was last updated in 2018, doesn’t seem to be actively maintained, and the README files were not helpful for my new-to-python eye, despite originally appearing promising.
This experience lead me to browsing pypi.org (The Python Package Index, a repository of python-language software) for “marc” and “rdf” packages, and I easily stumbled upon pybibframe. It is simple to use, and even offers the option to create an RDF/XML representation, which is what I’m using in my course.
Before I get to the steps required to convert sample data I extracted from the University of Toronto catalogue to RDF/XML, I want to explain how this python package does things a little differently than what I originally wanted. I was hoping to convert directly to RDF/XML using whichever vocabularies I feel like, because in my course we’re often looking at schema.org and Dublin Core predicates. However, by converting from MARC XML -> RDF/XML using pybibframe, I’m required to have some knowledge of BIBFRAME (the Library of Congress Linked Data model), because that is the model that this package uses. This isn’t shocking, given that bibframe is even in the name of the package, but BIBFRAME creates RDF data using its own vocabulary that’s expressed in the RDF, and pybibframe doesn’t appear to have any built-in functions that would create triples using other ontologies. While it does makes sense to use BIBFRAME as a librarian because it is being touted as the replacement to MARC21, I may need to investigate other tools that could cross-walk between my BIBFRAME outputs and other models/vocabularies, or look in to ways to augment the data depending on the parameters of future projects that I might undertake.
But enough about that, now for the actual conversion process!
- Convert from MARC21 to MARC XML using MarcEdit (documentation about this process can be found on the Illinois Library MarcEdit Libguide).
- Open Terminal (I’m using a mac), and after installing pybibframe using pip, run:
marc2bf -o resources.versa.json –rdfxml resources.rdf records.mrx
That’s it! To confirm that the file successfully converted, I ran the triples that corresponded to the first MARC21 bibliographic record through the W3C RDF validator, and it was a success! You can see the graph and validated triples below, and if you click on the graph you will open it in full size in a new window. My next steps (during future research days) will be to play with ways to handle all of string literals by maybe introducing other ontologies, or seeing what skills would be required to introduce other ontologies into the pybibframe package.
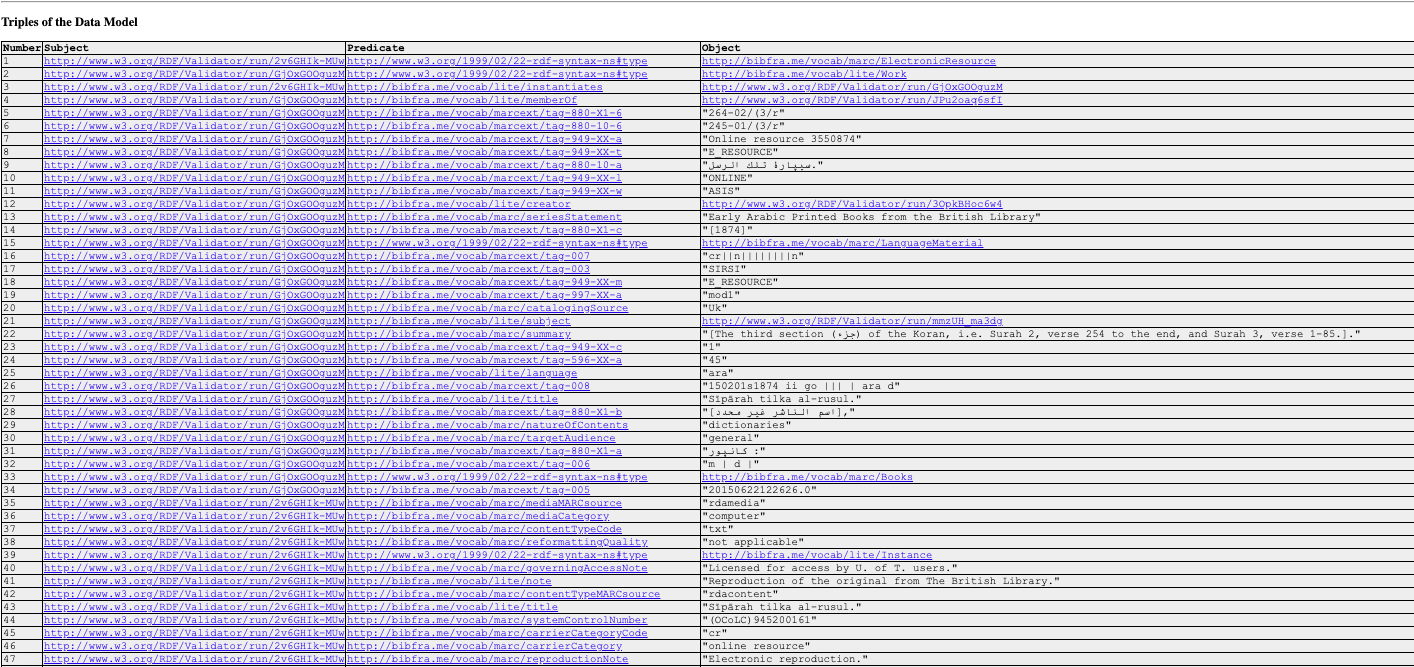
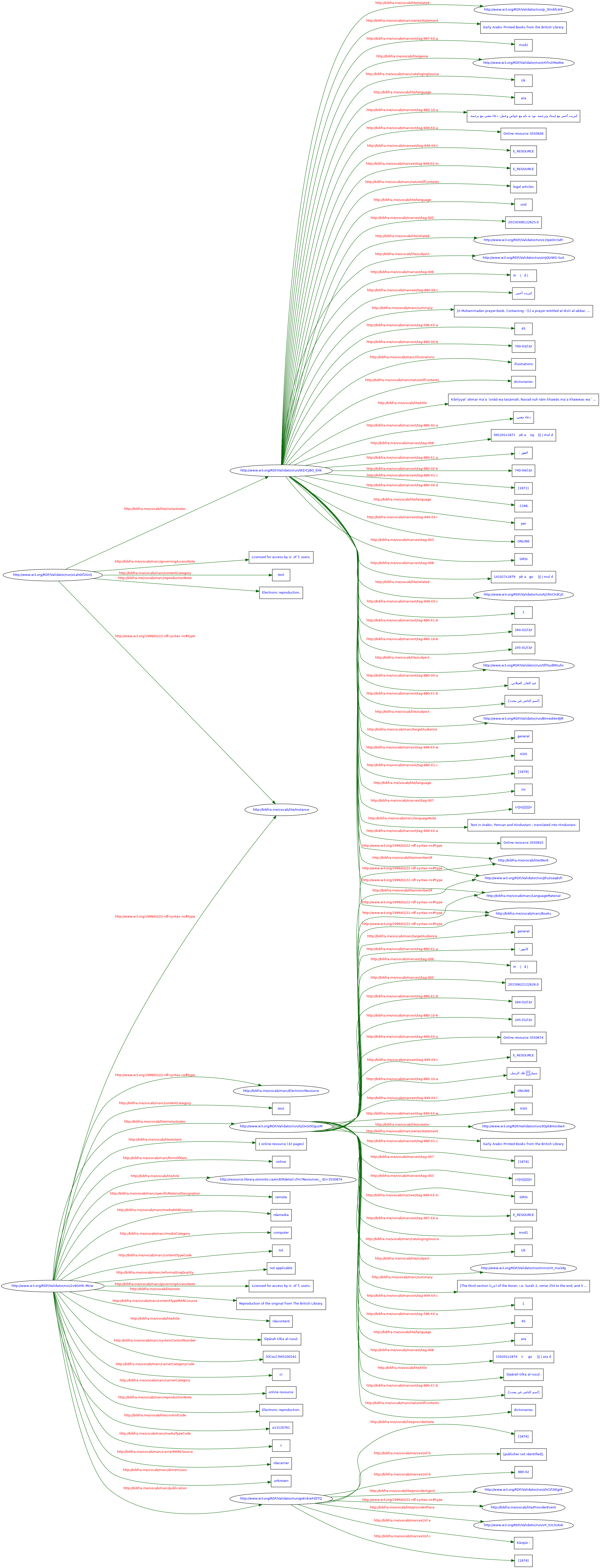
December 18, 2019
I’m looking forward to being a reviewer for Against the Grain, and have finally received my first book in the mail!
Without spoiling the review, I’m enjoying the book overall, and have found it to be insightful when considering larger questions around professionalization, working conditions, and my very recent past as an LIS student.
November 1, 2019
Rachel and I continued to work away preparing for PyCon Canada. I really should have kept better notes, but the day just flew by. I was so excited – and nervous – for PyCon Canada that I really didn’t have time to relax until after it was all done. That said, I’m looking forward to coming back to the linked data work we were doing, but starting from scractch and creating the dataset ourselves.
Because PyCon Canada fell on a weekend I didn’t take any research days for it. However, I thought I’d include it in this post because it was what Rachel and I were working towards. At PyCon, I mostly attended sessions in the PyData track, and had the opportunity to meet a lot of people who were not librarians, which I always find to be a rich way to spend my time. I worry often that as librarians we often make things harder for ourselves than they have to be, when people in other disciplines and professions are doing similar work, but we just don’t know about it.
I enjoyed learning about word2vec, in a presentation given by Roberto Rocha (a data journalist at CBC). Word2vec is used to determine document similarity, and in this case was presented in 3D through tensor. Leaving the session I couldn’t help but think of the interesting potential word2vec presents, maybe analyzing online reference questions…
Another thing that I enjoyed learning about, which was presented in the lightning talks, is gazpacho. Gazpacho is meant to be a simpler, easier-to-use replacement for (most) things that are currently done with beautifulsoup.
I also was grateful for the knowledge shared by Niharika Krishnan (Understanding Autistic Children Using Python), Stephen Childs (Data Viz with Altair), Serena Peruzzo (Data Cleaning), Jill Cates (Algorithmic Bias), Manav Mehra (Growing Plants with Python), Cesar Osario (Voice recognition using python and deep learning), Anuj Menta, and Josh Reed (Putting your data in a box). In addition, the conversations and connections I made with other people who are interested in tech and libraries was so valuable!
October 16, 2019
In preparation for a talk that Rachel Wang and I will be giving at Pycon Canada on November 17, 2019, I took my second research day. We’ll be presenting on gathering insights from linked data, using RDFlib and SPARQL queries.
What did we get up to?
- Explored some graphing databases – Neo4j and GraphDB. While both had great user interfaces, we decided to focus our efforts on GraphDB because it works well with RDF, and therefore RDFlib, whereas Neo4j uses Labelled Property Graphs. More information on this difference can be found on the Neo4j blog. GraphDB also has a tabular data to RDF loader, which is built off of OpenRefine, a tool we’re both already familiar with and hope to use more (there will be more on that later!).
- Explored loading data into GraphDB both through the RDF options and Tabular (OntoRefine) option. The Ontorefine option kept giving us problems – no matter the size of the file, it seemed to continue to load forever, or error out. This was frustrating because it was even the sample file provided by GraphDB to test this type of load.
- Developed SPARQL queries.
Below is a screenshot of the GraphDB interface with our sample wine dataset we were testing on.

July 30, 2019
For my first-ever research day, I decided to focus on skills that would be directly applicable in my current role. It wasn’t hard to decide that it would be invaluable to focus on developing skills with the system API that I work with nearly daily, but that I lack experience with, and a conceptual understanding of. I worked my way through the training manual, though I’m certainly left with some lingering questions. For example, some of the arguments seem not to be present in the manual, and some thoughts about constructing scripts using a combination of unix commands and local tools need some clarification.
Some of the things I learnt during my research day were:
- the way our databases are structured and which keys are used where
- server configuration (specifically, what does this Unicorn directory I keep using mean)
- what are Unix commands and the Bourne and Bash shells?
I now feel like I have a better basic understanding of how the API functions and which tools to use for which types of problems. However, I wish I would have a better understanding of exactly how to write some of the commands, because I have a sneaking feeling that many options were missing in the training manual. I think this because there are some scripts that I use, which were created before my time, that have inputs or outputs not defined in the manual. When I get back to work I’ll see if I can find the definitions in the API using another shortcut I learnt about “-x” to list tool, input and output options, and if not I’ll ask my supervisor for assistance.
All of this was made even better by the view! I took the opportunity to work at one of my local public libraries – the Hillsburgh Public Library. Recently opened as architecturally part heritage house, the library is on the water and has an exceptional view and beautiful collection, and the commute was 10 minutes instead of approximately 2 hours.


